
记忆系统的核心问题不是"怎么存",而是"存什么"和"什么时候不存"。
我们的 Agent 平台上有一个技能推荐 Agent。用户问"我有什么技能",Agent 调工具查了一遍,回答了。这轮对话被记进了长期记忆。
下次用户再问同样的问题,Agent 先从记忆里拿到上次的答案,回答了,然后又把这轮对话记进去。
第三次、第四次……记忆里全是"用户有 XX 技能"的重复条目,越来越多,全是噪音。
这是一个典型的"记忆只增不减"问题。根因很简单:工具查出来的结果不应该进记忆。“用户有什么技能"的答案是实时查出来的,随时可以再查,记下来没有意义。
但我们的系统当时没有这个判断——每轮对话结束,无脑写入。
这个问题促使我去认真研究 Claude Code 的记忆系统是怎么设计的。
02 Claude Code 的第一性原理:只记推导不出来的东西
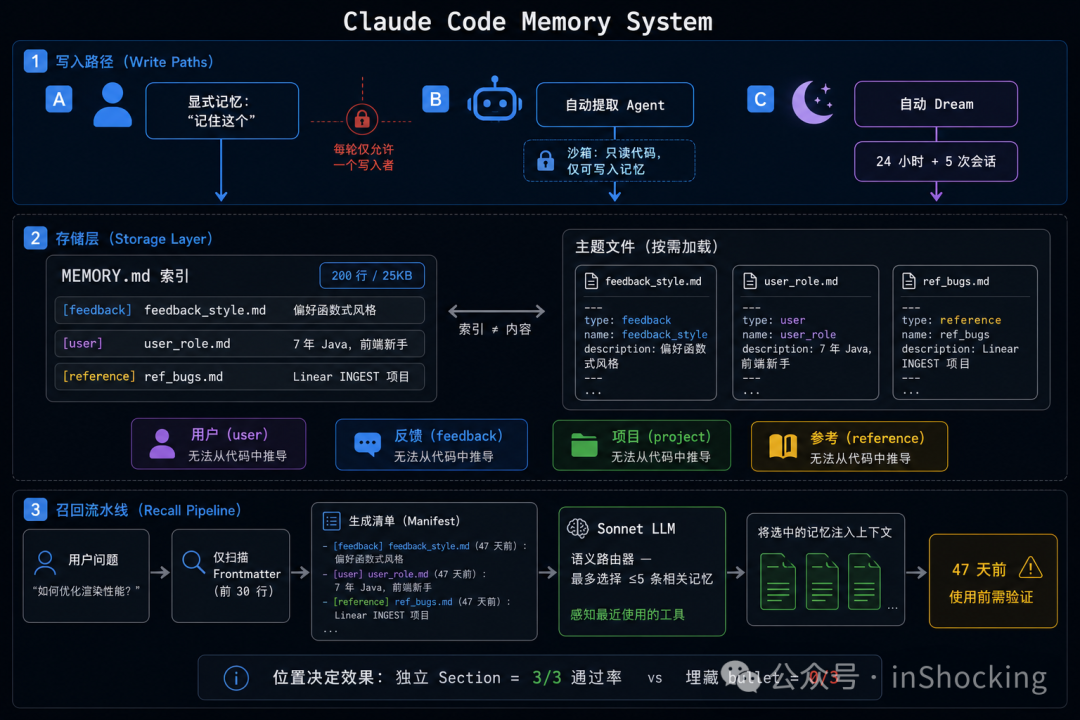
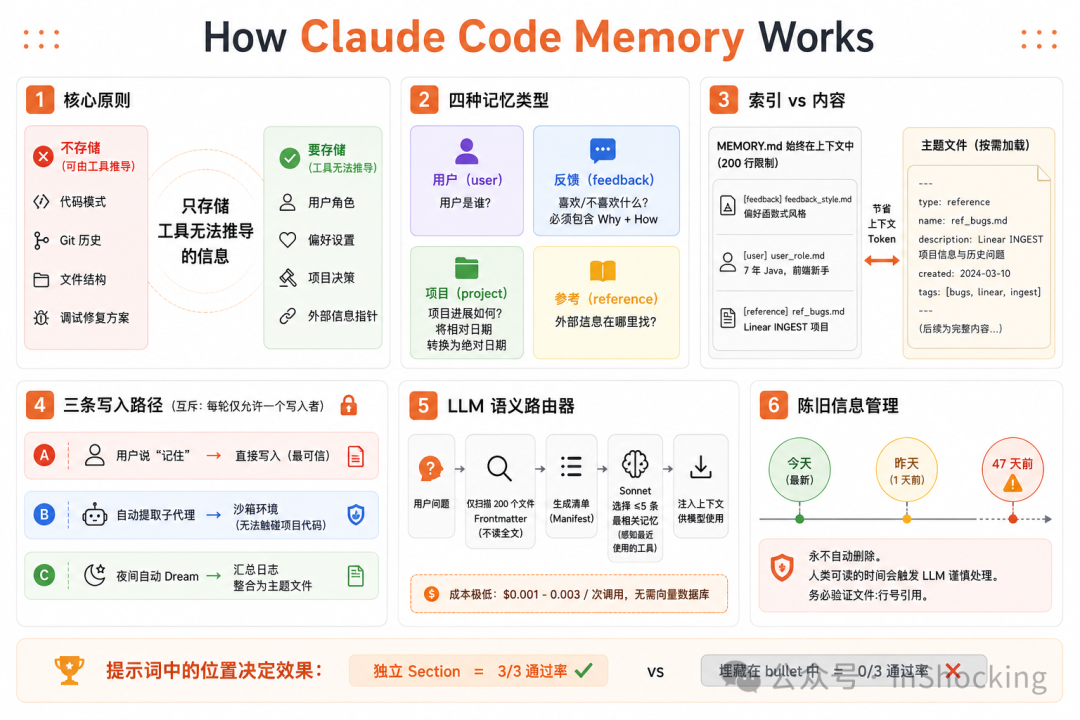
Claude Code 的记忆系统源码在 src/memdir/ 目录下。memoryTypes.ts 的第 5-12 行开宗明义:
Memories are constrained to four types capturing context NOT derivable from the current project state. Code patterns, architecture, git history, and file structure are derivable (via grep/git/CLAUDE.md) and should NOT be saved as memories.
关键词是 NOT derivable——不可推导的。
判断标准只有一个:这个信息能不能通过工具调用(grep、git log、读文件)推导出来?
- 代码模式?
grep能找到 → 不记 - Git 历史?
git log能查 → 不记 - 用户是数据科学家?没有任何工具能推导 → 记
- 用户讨厌 mock 测试?代码里看不出来 → 记
- 周四开始 merge freeze?git 里没有 → 记
基于这个原则,Claude Code 定义了封闭的四类型分类法(memoryTypes.ts:14-19):
export const MEMORY_TYPES = ['user', 'feedback', 'project', 'reference'] as const
| 类型 | 核心问题 | 典型内容 |
|---|---|---|
| user | 用户是谁? | “7 年 Java,刚转前端” |
| feedback | 用户喜欢/讨厌什么工作方式? | “不要在每次回复末尾总结” |
| project | 正在发生什么? | “2026-03-05 开始 merge freeze” |
| reference | 去哪找外部信息? | “Pipeline bugs 在 Linear INGEST 项目” |
这四类有一个共同特征:它们都是工具查不到的。
反面清单同样重要
memoryTypes.ts:183-195 定义了明确的不存清单:
export const WHAT_NOT_TO_SAVE_SECTION = [
'- Code patterns, conventions, architecture, file paths...',
'- Git history, recent changes...',
'- Debugging solutions or fix recipes...',
'- Anything already documented in CLAUDE.md files.',
'- Ephemeral task details: in-progress work, temporary state...',
'',
'These exclusions apply even when the user explicitly asks you to save.',
]
最后一句是精髓:即使用户明确要求,也不存。
源码注释解释了为什么:用户说"帮我记住这周的 PR 列表”,正确的做法是反问"有什么惊喜或意外的吗?"——只存惊喜部分,不存整个列表(快照,几天就过期)。
03 索引与内容分离:解决 context 膨胀问题
记忆系统有一个根本矛盾:记忆越多 → context 越满 → 留给实际工作的空间越小。
Claude Code 的解法是索引-内容分离(memdir.ts:34-38):
export const ENTRYPOINT_NAME = 'MEMORY.md'
export const MAX_ENTRYPOINT_LINES = 200
export const MAX_ENTRYPOINT_BYTES = 25_000
MEMORY.md 是一个目录文件,不是记忆存储本身。每条记忆一行:
- [用户偏好代码风格](feedback_code_style.md) — 函数式优先,不用 class 组件
- [Pipeline bug 跟踪](ref_pipeline_bugs.md) — 在 Linear INGEST 项目
- [用户画像](user_role.md) — 7 年 Java,刚转前端
源码注释解释了 200 行 / 25KB 的上限:
~125 chars/line at 200 lines. At p97 today; catches long-line indexes that slip past the line cap (p100 observed: 197KB under 200 lines).
有人可能一行写 1000 字符,200 行就 197KB 了。所以字节上限是第二道防线。
MEMORY.md 常驻 system prompt,只占几百 token。真正的记忆内容存在独立的主题文件里,按需加载。
04 用 LLM 选记忆,而非向量搜索
这是 Claude Code 最反直觉的设计。
大多数记忆系统用向量搜索——算 embedding,找余弦相似度最高的 top-K。Claude Code 没这么做。
findRelevantMemories.ts 的流程:
scanMemoryFiles()— 扫描所有 .md 文件,只读前 30 行(frontmatter)formatMemoryManifest()— 格式化为清单:"- [type] filename (timestamp): description"selectRelevantMemories()— 调用 Sonnet sideQuery,选 ≤5 个相关记忆- 注入被选中的记忆内容
Sonnet 选择器的 system prompt(findRelevantMemories.ts:18-24):
const SELECT_MEMORIES_SYSTEM_PROMPT = `You are selecting memories that will be useful to Claude Code
as it processes a user's query...
Return a list of filenames for the memories that will clearly be useful (up to 5).
Only include memories that you are certain will be helpful.
- If you are unsure, do not include it. Be selective and discerning.`
为什么不用向量搜索?因为语义相似 ≠ 实际相关。
用户说"帮我修这个 bug",向量搜索可能找到"上次修 bug 的经验"。但 LLM 能理解推理链:用户在调试数据库 → 需要之前关于数据库 mock 的教训。这种隐含关联,向量搜索做不到。
还有一个细节——工具感知(findRelevantMemories.ts:92-95):
const toolsSection = recentTools.length > 0
? `\n\nRecently used tools: ${recentTools.join(', ')}`
: ''
把"最近使用的工具"传给选择器。效果:用户正在用 Jira MCP → 不选 Jira 使用手册(已经在用了),但会选 Jira 的注意事项(“Jira 的 MCP 连接有时超时,需要重试”)。
每次召回成本约 $0.001-0.003,比向量数据库的基础设施成本低得多。
05 过期管理:一个被低估的细节
memoryAge.ts 里有一段代码,看起来很简单,但背后有深意:
export function memoryAge(mtimeMs: number): string {
const d = memoryAgeDays(mtimeMs)
if (d === 0) return 'today'
if (d === 1) return 'yesterday'
return `${d} days ago`
}
为什么用 “47 days ago” 而不是 ISO 时间戳?源码注释:
Models are poor at date arithmetic — a raw ISO timestamp doesn’t trigger staleness reasoning the way “47 days ago” does.
LLM 不擅长日期算术。给它 “2026-03-18” 它不会觉得旧;给它 “47 days ago” 它立刻意识到这可能过期了。
过期警告(memoryAge.ts:33-42):
if (d <= 1) return '' // 今天/昨天的记忆不警告
return (
`This memory is ${d} days old. ` +
`Memories are point-in-time observations, not live state — ` +
`claims about code behavior or file:line citations may be outdated.`
)
特别提到 “file:line citations”——因为用户报告过这样的问题:记忆说"在 src/auth.ts:42 有 validateToken 函数",但那个函数已经被重命名了。精确引用 + 过期 = 危险组合,LLM 说得越自信,错得越离谱。
还有一个关键设计:验证指令的位置比措辞更重要。
源码注释(memoryTypes.ts:228-238)记录了一次 eval 结果:
H1 (verify function/file claims): 0/2 → 3/3 via appendSystemPrompt. When buried as a bullet under “When to access”, dropped to 0/3 — position matters.
同样是"验证记忆中的文件引用"这条指令:
- 作为独立 section → 通过率 3/3
- 埋在其他 section 的 bullet 里 → 通过率 0/3
06 三条写入路径,互不干扰
Claude Code 有三条写入路径(extractMemories.ts、autoDream.ts):
路径 A:用户主动说"记住这个"——主 Agent 直接写入,最可信。
路径 B:每轮对话结束后,后台自动提取——一个 forked subagent,有严格的权限沙箱:
- 读任意文件
- 执行只读 shell 命令
- 写记忆目录
- 写项目代码
- 执行写命令(rm, mv)
- 使用 MCP 工具
即使提取 Agent 被 prompt injection 攻击,它也没有能力修改项目代码。
路径 C:Auto-dream——累积 24h + 5 个会话后触发,把零散日志整合成主题文件。
三条路径互斥(extractMemories.ts:121-148):
if (hasMemoryWritesSince(messages, lastMemoryMessageUuid)) {
return // 主 Agent 已经写了 → 跳过后台提取
}
一个 turn 只有一个写入者。
07 我们实际做了什么
回到我们自己的系统。
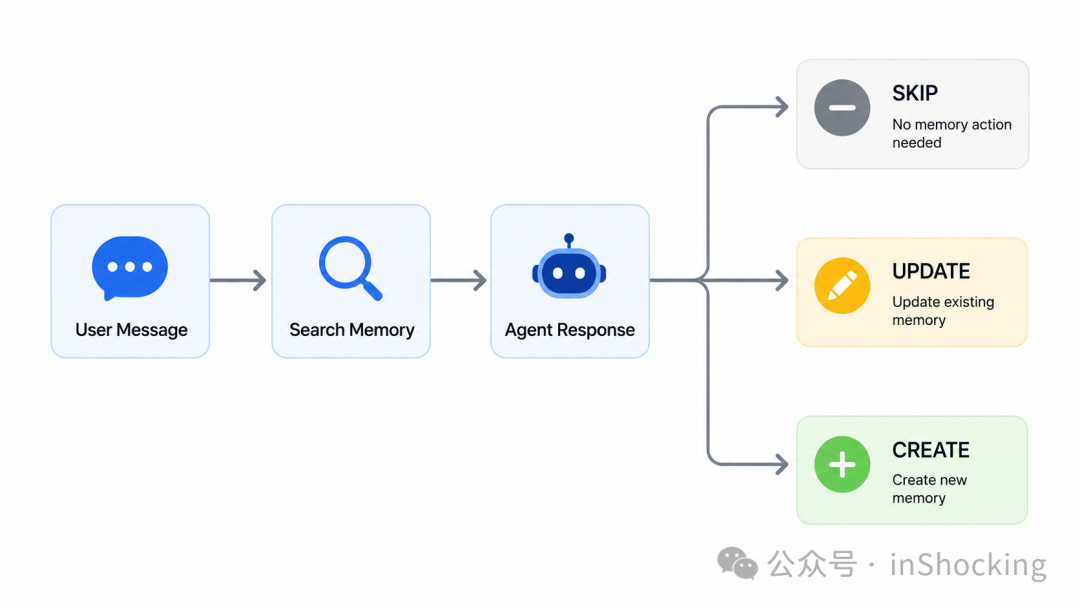
我们的 Agent 平台接入了一个外部记忆服务,它提供向量存储和语义检索能力。基本架构是:Agent 在每轮对话后调用记忆服务的 record 接口写入,在每轮对话前调用 retrieve 接口召回。
借鉴 Claude Code 的设计,我们实现了最核心的一个改动:Retrieve-Record 闭环。
原来的流程:
用户说话 → Agent 回复 → 把对话存进记忆服务
改造后的流程:
用户说话 → 先检索已有记忆 → Agent 回复 → LLM 决策
↓
SKIP(已有,不存)
UPDATE(有旧版,更新)
CREATE(全新的,存)
核心是在 record 之前加一步 LLM 决策:把本轮 QA pair 和已有的相关记忆一起传给模型,让它判断该做什么。
这个改动解决了"我有什么技能"的重复膨胀问题——第二次问同样的问题,SKIP,不写入。
一个踩过的坑
实现过程中遇到一个流式响应的问题:用 stream 方式调用 LLM 时,如果只取最后一个 chunk,会拿到空内容——因为流式响应的最后一个 chunk 通常只是结束信号,不含实际文本。
修复方式:改为聚合所有 chunk 的文本,而不是只取最后一个。这个坑在用流式 API 做结构化输出时很容易踩到。
08 还差什么
做完这些,我们对照 Claude Code 的设计做了一次差距分析:
| 设计点 | 我们的状态 |
|---|---|
| 只记推导不出来的 | prompt 层面约束,无代码强制 |
| 有反面清单 | SKIP 规则已实现 |
| 写入互斥 | 单体架构天然满足 |
| LLM 语义路由 | 目前直接用记忆服务 top-K |
| 年龄标签 | 时间字段有,但没用上 |
| feedback 带 Why + How | 偏好记忆和普通记忆一样处理 |
| Session Memory 安全网 | 压缩时无关键信息保护 |
| 定期记忆整合 | 无跨会话碎片合并机制 |
最容易落地的两个改动:
过期标签:记忆服务返回的记录通常有 updated_at 字段,在 retrieve 结果拼接时附加"X 天前记录"就够了,改动量极小,但能防止 Agent 盲信过期记忆。
LLM 精选:不需要替换记忆服务的向量搜索,在 top-K 结果之后加一步 LLM 筛选,把 10 条压到 5 条以内,减少 context 噪音。成本约 $0.001-0.003/次,收益明显。
09 一些真实的体会
记忆系统的质量取决于"不存什么",而不是"存什么"
Claude Code 的反面清单是 eval-validated 的——之前没有时,用户说"save this week’s PR list",Claude 就存了,产生大量 activity-log 噪音。加上反面清单之后才解决。我们自己的系统也是,加了 SKIP 规则之后,记忆库的噪音明显下降。
prompt 的位置和措辞都影响效果
Claude Code 团队用 eval 验证每条指令:同样的内容,作为独立 section 通过率 3/3,埋在 bullet 里通过率 0/3。这不是玄学,是可以测量的。我们在设计记忆决策的 prompt 时也发现,把"不记什么"单独列出来比混在其他规则里效果好很多。
“语义相似"和"实际有用"是两件事
向量搜索找的是语义相似,但 Agent 需要的是"对当前任务有用”。Claude Code 用 LLM 做语义路由,成本极低,但精准度比纯向量搜索高。我们还没做这一步,但这是下一个优先级。
本文基于 Claude Code 源码(src/memdir/、src/services/extractMemories/)的分析,以及在 Agent 平台接入记忆服务的实战经验。
评论