Karpathy 说"这里机会做出一款了不起的新产品"——而你现在就可以用现成工具搭一个属于自己的版本。
一、Karpathy 说了什么?
2026.4.3,AI 界的传奇人物 Andrej Karpathy 在 X 上发了一条长推,大意是:
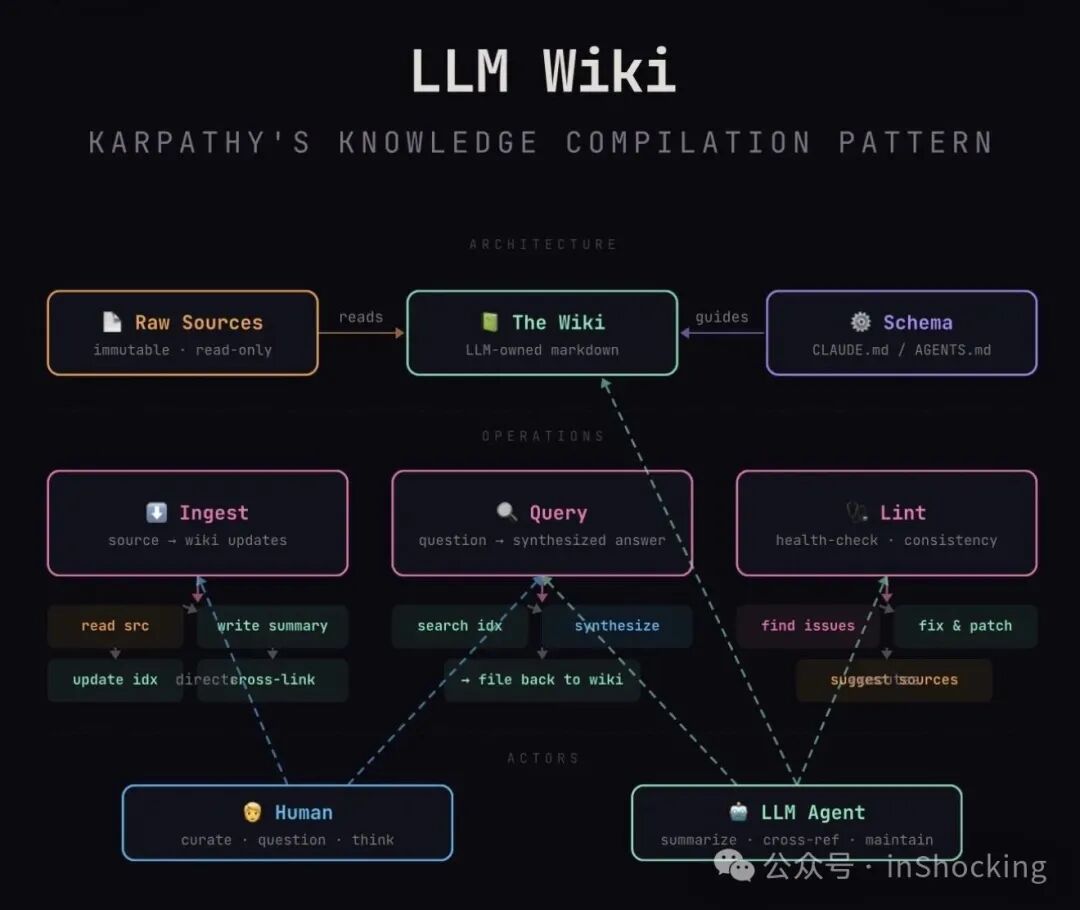
“我最近发现一件很有用的事:用 LLM 帮我为各个研究方向建立个人知识库。我把原始资料放进 raw/ 目录,然后让 LLM 逐步’编译’成一个 wiki(一堆 .md 文件)。wiki 包含摘要、反向链接,还会把内容归类成概念文章并互相引用。Obsidian 是我的前端 IDE。重要的是:wiki 的所有内容都由 LLM 编写和维护,我几乎不直接动它。”
他还提到:
- 知识库够大之后(他的大约 100 篇文章、40 万字),可以对它做复杂的 Q&A
- 他自己 vibe code 了一个小搜索引擎作为工具
- 会定期做"健康检查",让 LLM 找出矛盾信息、补全缺失内容、发现新的连接点
- 未来方向:合成数据 + 微调,让 LLM 把知识"烧进权重"
最后他说:“我觉得这里有机会做出一款了不起的新产品,而不只是一堆脚本拼凑。”
二、我是怎么搭的?
我几乎完全按照 Karpathy 的思路和小红书博主 Lucas|AI X Fintech 搭了一套个人 LLM 知识库,用的全是现成工具。
核心架构:三个目录 + 一份规范
llm-wiki/
├── raw/ ← 原始资料(只读不改)
├── wiki/ ──── symlink ───→ Obsidian Vault/llm-wiki/
└── CLAUDE.md ← 工作规范(Claude 读这个知道怎么干活)
关键设计:wiki/ 是一个指向 Obsidian Vault 子目录的软链接。这样 wiki 物理上住在 Obsidian 里,可以用图谱视图、双向链接、全文搜索——同时项目结构保持完整。
wiki 的内部结构
wiki/
├── index.md ← 所有页面的目录(每页一行:链接 + 摘要)
├── log.md ← 操作日志
├── concepts/ ← 概念页(每个核心概念一个 .md)
├── entities/ ← 实体页(人物、项目、工具、公司)
├── sources/ ← 每份原始资料的摘要页
└── outputs/ ← 查询产出(分析、对比表、综述)
规范文件 CLAUDE.md
这是整个系统的"大脑协议"。它告诉 Claude:
- 摄入(Ingest):当我把文件放进 raw/ 并告诉你处理时,先和我讨论要点,确认后再写 sources/、更新 index.md、创建/更新相关 concepts/ 和 entities/ 页面,最后在 log.md 追加记录
- 查询(Query):先读 index.md 找相关页面,深入阅读,综合回答并引用具体页面,有价值的回答存入 outputs/
- 健康检查(Lint):定期检查矛盾、孤立页面、提到但未建页的概念、过时信息
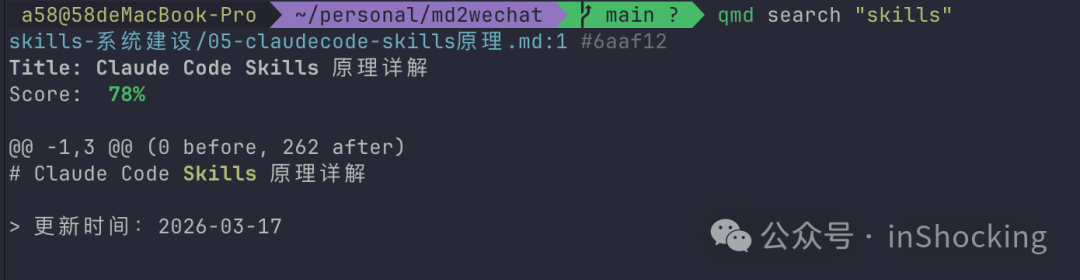
搜索引擎:qmd
Karpathy 说他 vibe code 了一个简单搜索引擎——我选择直接用开源的 qmd(Tobias Lütke,Shopify CEO 做的)。
它提供三种搜索模式,完全本地运行:
- BM25 关键词搜索 →
qmd search "关键词"(毫秒级,无需模型) - 向量语义搜索 →
qmd vsearch "描述需求"(需要嵌入模型) - 混合+重排 →
qmd query "问题"(BM25 + 向量 + LLM 重排,最佳质量)
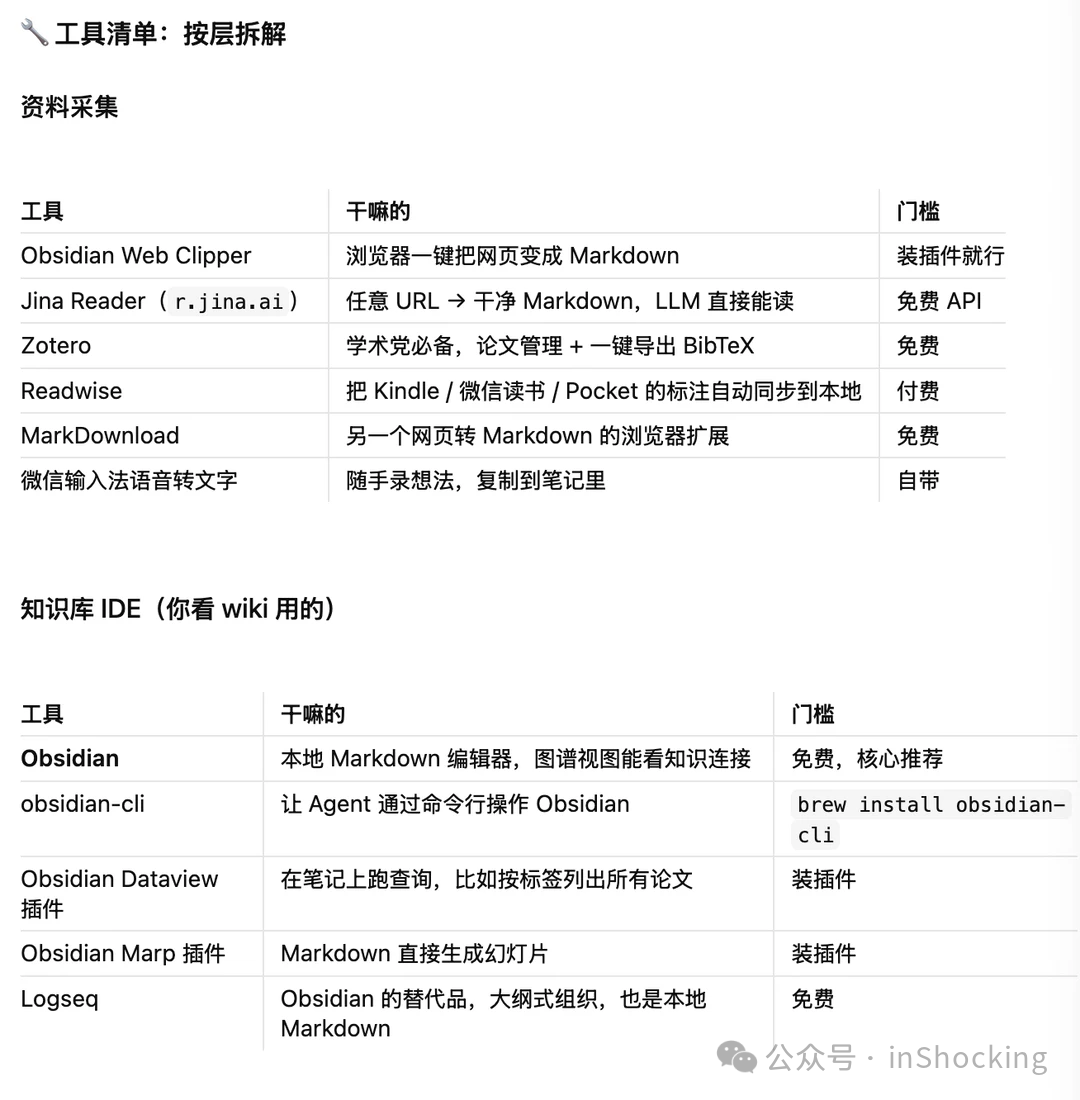
使用了哪些工具?
| 工具 | 角色 | 说明 |
|---|---|---|
| Claude Code | LLM Agent | 读文件、写 wiki、回答问题 |
| Obsidian | 前端 IDE | 查看 wiki、图谱视图、双向链接 |
| qmd | 本地搜索引擎 | BM25 + 向量 + LLM 重排,完全离线 |
| CLAUDE.md | 工作规范 | Agent 的"行为操作系统" |

三、实际处理了什么?
我把自己 Obsidian 里已有的 490 多篇笔记全部纳入了这套系统。经过一轮处理,wiki 里现在有:
14 个概念页,比如:
- agent-prompt-principles:从 Claude Code / Codex / Gemini 系统提示词横向比较中提炼的 12 条 Agent Prompt 设计原则
- trust-infrastructure:AI 工具竞争正在从能力竞争转向信任基础设施竞争
- skills-architecture:元工具模式,解决工具列表爆炸问题
- agent-memory:AI Agent 记忆机制,10 篇核心论文综述
6 个实体页,比如:
- openclaw:个人 AI 助手平台,AI Agent 操作系统
- memos:Agent 记忆管理服务,正在集成到技能市场
8 个源摘要页,包括月度 AI 工具雷达、Agent Web 研究集群、深度技术日志等
四、这套系统怎么用?
搭好之后,有三种使用姿势:
姿势一:摄入新知识
把文章、论文、PDF 丢进 raw/,告诉 Claude:
“处理 raw/这篇文章.pdf”
Claude 会先和你讨论要点,确认后自动:写摘要页 → 更新 index.md → 创建/更新相关概念和实体页 → 记录日志。
一篇文章可能触发 10-15 个页面的更新。
姿势二:跨笔记提问
直接问问题:
“我对 RAG 和向量数据库有哪些研究结论?” “我关于 Agent 架构的核心观点是什么?” “我用过哪些 AI 工具?各有什么优缺点?”
Claude 先读 index.md 找到相关页面,深入阅读后综合回答,引用具体页面,有价值的回答还会存进 outputs/。
姿势三:健康检查
定期告诉 Claude:
“lint”
它会检查:页面间有没有矛盾?有没有孤立页面?有没有提到但没建页的概念?有没有过时信息?
五、和 Karpathy 的思想一致吗?
高度一致,有几处增强。
一致的核心: raw/ 原始资料 + LLM 编译 wiki + Obsidian 作为前端 + LLM 维护一切 + Q&A + 健康检查,这五点完全对应。
额外增强的地方:
1. qmd 比 Karpathy 的自建搜索引擎更强
Karpathy 自己 vibe code 了一个"简单搜索引擎"。qmd 提供了完整的混合搜索(BM25 + 向量 + LLM 重排),完全本地,开箱即用。
2. CLAUDE.md 把工作流编码化
Karpathy 的方式更像"对话式"——每次告诉 LLM 怎么做。CLAUDE.md 把摄入/查询/健康检查的流程固化成规范,下次打开新对话,Claude 直接读规范就知道该怎么干。
3. Obsidian 的集成更深
wiki 直接住在 Obsidian vault 里,[[wiki-links]] 双向链接天然可用,还可以用图谱视图看概念之间的关系。
Karpathy 还没实现的:他提到未来想做合成数据 + 微调,让 LLM 把知识"烧进权重"。这个我们也还没做——但这可能是这套系统的终极形态。
六、能推广到企业吗?
完全可以,而且潜力更大。
个人知识库解决的是"一个人记不住所有知识"的问题。企业知识库解决的是"一个团队的知识分散在每个人脑子里"的问题——后者的痛点其实更深。
企业版的架构调整
企业 LLM Wiki
├── raw/ ← 会议记录、设计文档、技术方案、外部资料
├── wiki/
│ ├── concepts/ ← 公司技术概念(内部框架、业务术语)
│ ├── entities/ ← 系统、服务、团队、人员
│ ├── projects/ ← 项目页(新增)
│ ├── decisions/ ← 技术决策记录 ADR(新增)
│ └── runbooks/ ← 运维手册(新增)
├── CLAUDE.md ← 团队协作规范
└── .git/ ← 版本控制(新增)
企业场景的具体价值
- 新人入职:新员工问"我们的消息系统架构是什么?",直接从 wiki 拿到答案,不需要打扰同事。
- 技术决策沉淀:每次架构评审后,把讨论和结论摄入 wiki,下次类似决策时直接查历史依据。
- 跨团队知识共享:A 团队研究过的技术方案,B 团队通过 wiki 直接获取结论,不用重复调研。
- 文档自动维护:每次有新的技术文档、RFC、post-mortem,让 LLM 自动更新 wiki 里相关的概念页和实体页。
企业版需要额外解决的问题
- 权限控制:不是所有 wiki 页面都该所有人看。需要分层访问控制。
- 多人协作:多个人同时往 wiki 里写,需要冲突解决和版本管理(git 是天然答案)。
- 知识审核:LLM 写的内容需要人工确认才能"发布",避免错误信息传播。
- 隐私和安全:企业知识不能上传到外部服务,需要本地部署的 LLM 和搜索引擎(qmd 正好完全本地)。
七、总结
Karpathy 描述的是一种新的知识管理范式:LLM 不只是问答工具,而是知识的编译器、维护者和分析师。
我们搭的这套系统,用 Claude Code + Obsidian + qmd + CLAUDE.md,花了不到一个下午,就跑通了这个范式。
整个系统的核心逻辑只有一句话:
原始资料永远存在 raw/,知识永远住在 wiki/,LLM 是唯一的编辑者。
Karpathy 说这里有机会做出一款了不起的产品。也许是的。但在那款产品出现之前,你现在就可以用这几个工具,搭出一个属于自己的版本。
工具清单: Claude Code(LLM Agent)/ Obsidian(前端 IDE)/ qmd(本地混合搜索引擎,tobi/qmd)/ CLAUDE.md(工作规范)
评论